Building Kubernetes Applications for Azure Stack Edge Mini

Based on the project experiences working with Azure Stack Edge Mini’s in 2021 in this article we will share a point of view on building microservices-based Artificial Intelligence (AI) distributed Kubernetes applications for Azure Stack Edge Mini’s for knowledge mining on the Edge and offer some comments about the qualities of a sample solution architecture. It is a typical requirement across different industries to be able to gain meaningful insights from the variety of structured, semi-structured and unstructured data in the field including situational awareness use cases. Using commodity hardware and a Pub-Sub (publisher-subscriber) pattern with Kafka event streaming platform yields additional benefits for scalability and reliability of the solution.
If you are reading this article we assume you are already familiar with Azure Stack and Azure Stack Edge Mini, in fact, you can always find more information about Azure Stack Edge Mini here. From the communications perspective Azure Stack Edge Mini devices can operate both when wired to the network or via a wireless network as described here.
If interested, you can order an Azure Stack Edge Mini device(s) type available in your country for your organization on Azure Portal according to the current pricing. Specifically, we have got Azure Stack Edge Mini R with 16 cores, 48 GB RAM total (with 32 GB RAM usable) and circa 1 TB of storage which allows us to deploy and run some sophisticated Artificial Intelligence (AI) apps on a single node Kubernetes cluster.
When building Artificial Intelligence (AI) apps for a specific workload on the Edge we will have to identify concrete requirements and make certain technology choices. We’ve already identified the necessary assumptions in this article. And in this article we focus on a distributed solution architecture to make the same use case work for Azure Stack Edge Mini devices (at least 2 and possibly a swarm of multiple devices) and how Kafka event streaming platform can help with data integration between devices.
Architecture and Micro-services
A sample solution architecture, its qualities and the list of micro-services have already been provided in this article.
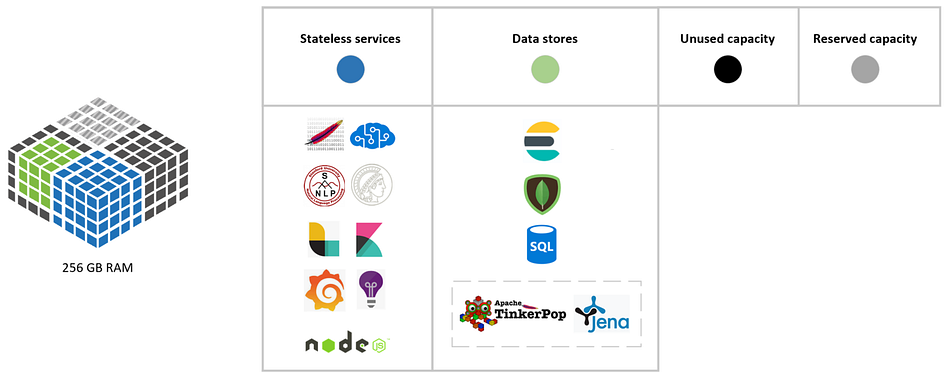
Because an individual Azure Stack Edge Mini device has less resources comparing to Azure Stack Edge device, we can split the overall workload into 2 sub-workloads which can be deployed on multiple Azure Stack Edge Mini devices without sacrificing performance of the solution. In this distributed architecture the 1st sub-workload is dedicated to the Content Exploration Tool under the assumption that document cracking is done elsewhere and the data is provided to this component type via Web API. A sample solution architecture of Content Exploration Tool component is provided below.

The 2nd sub-workload is dedicated to Content Cracking Pipeline under the assumption that files (documents, images, audios, etc.) will be available through the storage mechanism (say, a dedicated container with mounted Persistent Volume for persistent storage on Azure Stack Edge Mini or Azure Stack Edge or a Blob Storage on Azure Stack Hub) and the cracked data will be communicated to Azure Stack Edge Mini devices running Content Exploration Tool component. This data integration can be achieved with the help of Kafka event streaming platform which may serve the role of a glue between Content Cracking Pipeline components and Content Exploration Tool components. Different types of data such as master data (definitions of problem domain and insights) or transactional data (extracted data: entities, key words, triples, etc.) may be communicated by means of different Kafka topics. A sample solution architecture of Content Cracking Pipeline component is provided below and highlights the connectivity with Kafka.

Noteworthy: In the sample solution architecture for Content Cracking Pipeline component we highlight a uni-directional flow to Kafka to be able to publish the results of document cracking (extracts) as transactional data for consumption by Content Exploration Tool components (subscribers). Also in the sample solution architecture for Content Exploration Tool component we highlight a bi-directional flow to Kafka because some master data (problem domain definitions or insights) may originate from one instance of the component (Content Exploration Tool) which need to be distributed to other instances of the component, for these purposes Content Exploration Tool components will publish master data and subscribe to its changes on dedicated channels via Kafka topics.
Data Integration
Thus Kafka is an integral part of the solution architecture from the data integration perspective. To deploy Kafka cluster on Kubernetes we chose to leverage Strimzi. This Kafka cluster may be deployed on a separate Azure Stack Edge Mini device or co-located on one of the devices which already hosts either Content Exploration Tool or Content Cracking Pipeline depending on the resources available.
To integrate Kafka cluster into the solution architecture we have to expose it (Kafka cluster) properly and also write code to interact with it. For the sake of simplicity we exposed Kafka cluster (via its external bootstrap service) as NodePort per guidance here. The illustration below depicts the result of Kafka cluster deployment on Azure Stack Edge Mini device.

Noteworthy: Strimzi Kafka external bootstrap service allows to expose Kafka cluster for external connections. The required configuration includes adding a listener element with type nodeportto the Strimzi Kafka cluster definition YAML file, after that this new service can be seen via kubectl get svc -n kafka command as shown above.
After Strimzi configures everything inside the Kubernetes and Kafka cluster for you, you need to just specify IP address & port to connect to it. To write the integration code which interacts with Kafka cluster we chose to leverage Confluent .NET Core client library. In fact, you may choose from different libraries for different languages as you would like, a suggested list of libraries is provided in the table below.
Publisher and Subscriber components have been implemented as separate containers in Kubernetes cluster on Azure Stack Edge Mini devices running Content Exploration Tool as Web API containers (for example, .NET Core) for on-demand execution or as Azure Function containers running functions for continuous execution on schedule.
A pseudo-code for a minimalistic configuration of Publisher (Producer in Kafka terms) and Subscriber (Consumer in Kafka terms) components while using Confluent.Kafka .NET Core Nuget package may look like the following:
Noteworthy: Please notice port 30348 which is the exact port for Strimzi external bootstrap service highlighted earlier (your port will be different, 30348 was just a port which we highlighted on screenshots in this article for consistency).
Please follow the official code guidance and examples from Confluent for .NET Client library for Kafka here.
Noteworthy: In case you prefer to manipulate Kafka cluster over HTTPS instead of using a client library, Strimzi provides an HTTP Bridge capability described here. Then you can write integration code using generic HTTP(S) libraries in the language of your choice.
Finally to effectively develop, debug and troubleshoot all things Kafka we need a convenient command line interface or user interface. To review the state of Kafka cluster on-demand in a Web GUI we chose to leverage kafka-ui which was deployed as a separate container in Kubernetes cluster on Azure Stack Edge Mini devices (for both Content Exploration Tool and Content Cracking Pipeline types of components). The illustration below depicts Kafka UI user interface when connected to Kafka cluster deployed on Kubernetes.

Noteworthy: To configure Kafka UI connection to Kafka cluster we specified IP address & port as environment variable KAFKA_CLUSTERS_0_BOOTSTRAPSERVERSas shown above.
Resource allocation
A sample resource allocation has been already provided in this article here. However the specifics of working with Azure Stack Edge Mini devices is that we have less resources available comparing to Azure Stack Edge devices.

Similarly the resource allocation for Content Cracking Pipeline can be performed within the resource boundaries of Azure Stack Edge Mini device.
Deployment Automation and DevOps
Deployment considerations for DevOps and GitOps for Azure Stack Edge and Azure Stack Hub have already been provided in the articles here and here.
Noteworthy: When working with newer GitHub repositories with the default branch called main (instead on master) while setting up Azure Arc for Kubernetes GitOps configuration you can leverage --git-branch=main operator parameter per guidance here and as illustrated below

Also please note that when using multiple Azure Arc for Kubernetes GitOps configurations on the same device, the memcached container pod will be shared between them which makes it a consideration when deleting configurations selectively (this can be seen in the lower right corner of the screenshot above).
Disconnected mode and App sideloading
The app sideloading considerations for a disconnected mode have been already provided in this article.
Noteworthy: When you operate in a disconnected or air-gapped environment, it may be necessary to securely transfer the software and data which includes container images, utilities, document files, etc. to the field for application sideloading into devices. Practically, Azure Stack Edge Mini devices may be used in conjunction with the rest of Azure Stack family of devices such as Azure Stack Edge, Azure Stack Hub or Azure MDC (Modular Data Center). The illustration below depicts a sample secure transfer flow for container images in the field to Azure Stack Hub (ASH) where you may have Azure Container Registry (currently in Private Preview) or Docker Container Registry v2 (on Kubernetes cluster) installed

Also please note that for this sample scenario we used SecureDrive as a secure media and a number of command line utilities on Windows such as robocopy and pscp (PuTTY scp) to securely transfer the necessary container images as tar archives to Azure Stack Hub with Container Registry with the help of intermediary Ubuntu Linux VMs (jump-boxes). Azure Stack Hub may then serve the purpose of an artifact hub to facilitate deployment of Kubernetes applications to Azure Stack Edge Mini devices as necessary.
Showcase
If you would like to see an example of a sophisticated Artificial Intelligence (AI) app deployed on Azure Stack Edge using GitOps, you are welcome to watch a Channel 9 video here. Enriched Search Experience Project sample Kubernetes app on Azure Stack Edge is a proof-of-concept project and leverages circa 30 different container images to implement a knowledge mining workload on the edge. Please note that the application showcased in the video may have similar but not exactly the same architecture to the one described in this article.
Disclaimer
Opinions expressed are solely of the author and do not express the views and opinions of author’s current employer, Microsoft.
Books you might enjoy reading
You might enjoy reading the following books you have probably noticed on the front cover of this article:
- “Kafka The Definitive Guide: Real-Time Data and Stream Processing at Scale” by Neha Narkhede, Gwen Shapira & Todd Palino (2017) (link)
- “Kubernetes Up & Running: Dive into the future of infrastructure” by Brendan Burns, Joe Beda & Kelsey Hightower (2017, 2019) (link)
- “Kubernetes Patterns: Reusable elements for designing cloud-native applications” by Bilgin Ibryam & Roland Huß (2019) (link)
- “Managing Kubernetes: Operating Kubernetes clusters in the real world” by Brendan Burns & Craig Tracey (2018) (link)
- “Kubernetes Operators: Automating the container orchestration platform” by Jason Dobies & Joshua Wood (2020) (link)
- “Building Secure & Reliable Systems: Best Practices for Designing, Implementing and Maintaining Systems” by Heather Adkins, Betsy Beyer, Paul Blankinship, Piotr Lewandowski, Ana Oprea & Adam Stubblefield (2020) (link)

{kind=link}