Building Kubernetes Applications for Azure Stack Edge

Based on the project experiences working with Azure Stack Edge in 2020 in this article we will share a point of view on building microservices-based Artificial Intelligence (AI) Kubernetes applications for Azure Stack Edge for knowledge mining on the Edge and offer some comments about the qualities of a sample solution architecture. It is a typical requirement across different industries to be able to gain meaningful insights from the variety of structured, semi-structured and unstructured data in the field including situational awareness use cases.
If you are reading this article we assume you are already familiar with Azure Stack and Azure Stack Edge, in fact, you can always find more information about Azure Stack Edge here.
If interested, you can order an Azure Stack Edge device type available in your country for your organization on Azure Portal according to the current pricing. Specifically, we have got Azure Stack Edge Pro R with 24 cores, 1 GPU, 256 GB RAM and plenty of storage which allows us to deploy and run some sophisticated Artificial Intelligence (AI) apps on a single node Kubernetes cluster.
When building Artificial Intelligence (AI) apps for a specific workload on the Edge we will have to identify concrete requirements and make certain technology choices. In this article we assume one of the feasible scenarios with the following details:
- App is a microservices-based containerized Artificial Intelligence (AI) app for knowledge mining on the Edge. Content (the data) is heterogeneous and multi-language, and includes documents, images and media (audio and video). After ingesting the data into the system, the information is extracted by the Content Cracking Pipeline and includes key phrases, linked entities and triples. While using the app users may explore various entities and topics, and gain meaningful insights to validate or invalidate their hypotheses.
- Complete web application and services (web APIs). The front-end is a Single Page Application (SPA) consuming JSON data over HTTP(S) from the back-end. The back-end itself is a collection of RESTful APIs exposed as JSON data over HTTP(S).
- Services are relatively small, containerized, independent units with their own persistent stores if applicable.
- App is deployed on Azure Stack Edge(s) through GitOps and its User Interface (UI) is available to users in a web browser.
Architecture
Because Azure Stack Edge is a managed appliance by Microsoft, we logically assume the first-class support of the first-party Microsoft Cognitive Services there and the decision-making process while selecting solution components may look like the following:
- First, choose the appropriate first-party Microsoft Cognitive Services containers which may be either Generally Available (ready for production) or in Preview (recommended for POCs).
- Second, choose the appropriate Open-Source Software (OSS) components according to their licenses.
- Third, decide in favor of purpose-built components (custom code) or choose the appropriate third-party components from ISVs according to their licenses.
It will also be helpful to keep an eye on the updates about new improved versions of existing Microsoft Cognitive Services and general availability of new Microsoft Cognitive Services in the Cloud and on the Edge (as containers). For example, the update from January 29 2021 here describes the new version of Microsoft Cognitive Services Text Analytics Named Entity Recognition in the Cloud. The list of Microsoft Cognitive Services provided as containers can be found here.
There may be many languages to choose from for implementing the front-end and back-end for the application. We would like to make the application available to users in a web browser, thus we are building a Web app (front-end), and the Web APIs (back-end) to support it.
JavaScript front-end frameworks are very popular, feature rich and well supported nowadays, for example, React, Angular, Vue, etc. In case you are interested in building a web front-end on the .NET stack you may consider ASP.NET Blazor. In this article we assume we decide to build a Single Page Application (SPA) in React (+ Redux), then we may take advantage of one of React UI component libraries such as Material-UI, React Bootstrap, Semantic UI React, etc. to speed up the development of the user interface without reinventing the wheel. Overall, your front-end will be more robust if you start building it using TypeScript from the get-go. While building UI we will likely need some additional packages which possibly implement some specific complex UI controls, when choosing those it will be beneficial to pick the ones which are well-maintained and come with TypeScript typings already provided.
For the back-end the selection will be pretty wide. In this article we assume we standardize around JavaScript stack and pick NodeJS and Express to be the backbone of the back-end. However, you may want to implement the back-end Web APIs in other languages such as ASP.NET Core (MVC) and Entity Framework Core, or Python and Django macro-framework and Django REST framework, or one of Python’s micro-frameworks like Flask or Sanic, or using Go (golang) net/http package, etc.
In addition to the back-end Web APIs (server-side) we may also leverage Azure Functions containers which provide a convenience of on-demand and scheduled execution as well as allow to conveniently incapsulate certain workflows. Azure Functions containers currently support .NET, NodeJS, Python, Java, etc. runtimes and in this article we will stick to NodeJS runtime as well for the purposes of standardization described above.
The following diagram illustrates the entire sample solution architecture:
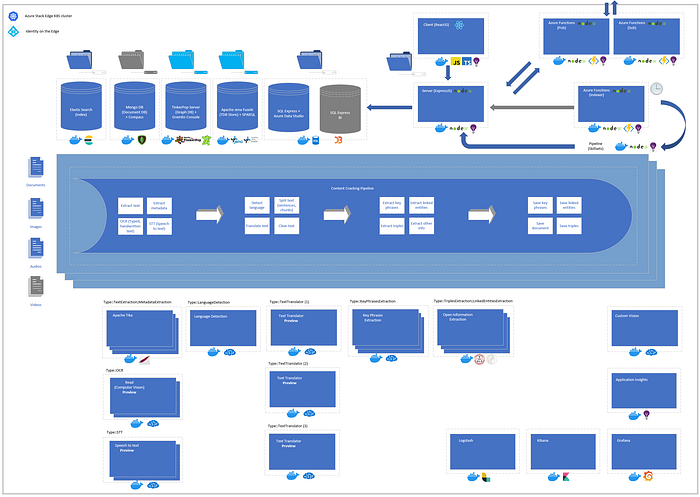
Noteworthy: Please note that in the contrast with directly managing your persistent volumes in Kubernetes cluster, for Azure Stack Edge you define your Persistent Volumes (PVs) definitions as File Shares (SMB or NFS) on Azure portal and then associate them to Kubernetes objects such as Deployments via Persistent Volume Claims (PVCs) referring to the File Shares by name. File Shares may be local to the device (disconnected scenarios) or associated with Azure Cloud Storage (connected scenarios). In case you experience issues with POSIX-compliant storage, for example, in case of MongoDB using WiredTiger storage engine, you may always take advantage of the hostPath approach described here which uses a directory on the Kubernetes node to emulate network-attached storage.
Micro-services
In micro-services-based solution architecture services are small, independent units with their own persistent stores. The sample app referred to in this article is relatively small. The sample list of 28 micro-services is presented in the table below:
Choosing the appropriate data stores is an important task when building your app(s). Often solution architectures combine data stores of different kinds. While full text index is typically foundational for search applications in general, we found non-relational data stores suitable for handling “master” data, relational database (also with JSON support) — for transactional data, graph databases help to manipulate with connected graphs (nodes, links) using graph traversals, and specialized triple stores (TDBs) help to query triples (tuples) using pattern matching.
There may be multiple choices (*) considered for Open Information Extraction (OIE) triples extraction. In this article we highlight only 2 of them which are Stanford Core NLP (Stanford NLP Group) and ClausIE (Max-Planck-Institut für Informatik).
Central for the data ingest process is the Content Cracking Pipeline(s) written in NodeJS which orchestrates the extraction of different types of information and implements all the necessary supportive skills. Once the ingest is completed the end users will be able to query and explore information in the convenience of a web browser.
Azure Cognitive Service Custom Vision portal allows to take advantage of Machine Learning (ML) algorithms provided by Microsoft and bring your own data for model training to build, for example, object detection and image classification models for specific use cases. The models you train and test in Custom Vision portal can be exported in different formats including exporting a Docker container definition which can be used to deploy your containers in the Cloud or on the Edge for inference. Cloud and Edge capabilities may be combined to perform ML inferencing on Azure Stack Edge, the general guidance about this use case is described here. In case you build your ML models from scratch (say, in custom Python code) you may consider MLOpsPython reference architecture which helps to operationalize your custom code for production. If the requirement is to train your models on-premises, you may consider deploying and using Kubeflow on Azure Stack Edge.
Noteworthy: Many of the containerized micro-services may already have a management User Interface (UI) baked-in and it is just a question of exposing right ports and launching your web browser, for example, if you need to debug something (containers with Type = Debug in the table above). But for the ones which do not it would make sense to find the appropriate management User Interface (UI) option(s) which will likely speed up development and troubleshooting efforts. For example, all first-party Microsoft Cognitive Services containers provide a convenient landing page and Swagger documentation for all the Web APIs, Mongo Express container (NodeJS app) with a simple configuration provides a management Web UI for MongoDB container(s), and for accessing Microsoft SQL Server Express container you may use a cross-platform Azure Data Studio tool (downloaded from here) and installed on your local computer which has access to the Kubernetes cluster on Azure Stack Edge. For the purposes of debugging and troubleshooting exposing your management User Interface containers via NodePort might be just fine.
Resource allocation
When building Kubernetes applications, it would be important to take a proper care of the initial resource allocation (requests and limits, etc.), have reasonable margins in place (to possibly accommodate for the future ad-hoc needs and prevent the shortages) and ensure the ongoing resources monitoring for smooth operations. Azure Stack Edge device specs define appropriate resources available such as CPUs, RAM, Disk, Network, etc. Practically, it would be reasonable to reserve about 20% of device’s resource capacity for system operations and manage the rest of 80% for the purposes of your apps.
Specifically, for Azure Stack Edge Pro R device we have got 256 GB RAM available. From the memory allocation perspective, we can divide our app’s demands into following 4 categories:
- Stateless services: These micro-services will implement different functions required for the solution to operate, for example, it could be Microsoft Cognitive Services containers for text analytics detecting a language or extracting key phrases from the text.
- Data stores: These micro-services will serve the purpose of data stores and store the data according to the associated persistent volumes, for example, it could be relational, non-relational or graph databases used in the solution. Data stores may be persistent or non-persistent depending on the requirements and usage rationale.
- Reserved capacity: This could represent about 20% of reserved capacity for system operations.
- Unused capacity: And this could be the rest of the capacity on the device.
If we assume that our app is memory-bound, the diagram below depicts a sample memory resource allocation for your app on Kubernetes cluster:

Empirically you will likely find the necessary amount of resource allocated per container for its optimal performance. In fact, for Microsoft Cognitive Services containers these initial recommendations have been already provided here along with the information about which containers are Generally Available and which are in Preview. Specifically, for Text Analytics containers (Language detection, Key phrase extraction, Sentiment analysis) the information can be found here, for Speech to text container — here, and for OCR (Read) container — here.
During operations you will also be able to use kubectl commands on behalf of your dedicated user to check on resource allocation and usage cluster-wide (even outside of your dedicated namespace associated to your user) which is very convenient (to have Administrator read-only permissions on the cluster).
Noteworthy: When you configure a compute role as a part of a device configuration you will be allocated a certain amount of resource on Azure Stack Edge device to be used for your apps by default. For example, we could have got the initial allocation of 64 GB RAM (from the total of 256 GB RAM) and 12 CPUs (from the total of 24 CPUs). In case your apps will require more resources allocated on the cluster for the workload you are implementing, you will be able to increase the allocated resources after the initial configuration of the device. This step can be performed by using the following PowerShell cmdlets after you remotely connect to the cluster from your computer on a Support Session (with Administrator privileges):
- Set-AzureDataBoxEdgeRoleCompute: Command to change resource allocation of the cluster. The syntax of this command is Set-AzureDataBoxEdgeRoleCompute [-JsonFormat] [-Name <string>] [-MemoryInBytes <long>] [-ProcessorCount <int>] [<CommonParameters>]. For example, -MemoryInBytes parameter could be 137438953472 for 128 GB (or can specify 128GB explicitly instead) and -ProcessorCount parameter could be 18 for 18 CPUs.
- Get-AzureDataBoxEdgeRole: Command to retrieve the definition of the IOT role under which compute resources have been allocated. For example, “IotRole” which can be used as -Name parameter in the previous command.
Please also note that after you change (increase or decrease) the resource allocation the cluster will be restarted, and all existing (already deployed) pods will be re-deployed from scratch.
There may be numerous attributes of an applicable Solution Architecture for a specific problem. In micro-services-based architectures there may also be some specific challenges. For example, we will just spotlight one particular with handling transactions across multiple micro-services or distributed transactions. One way of tackling this challenge may be to use the eventual consistency approach with compensating transactions (undo). Overall, in this scenario we will follow DRY and KISS (keep it short and simple) principles, and focus on the following select attributes of the solution architecture for the problem on-hand:
Functionality
The functionality of the app is well and laconically described by Mike Tse here as “Knowledge Mining on the edge unlocks latent/trapped insights from your content locally on your Azure Stack Edge appliance, even when you’re not connected to the internet. You simply copy over unstructured files (images, documents or multimedia), apply a variety of AI capabilities (or skills) to extract valuable information that’s trapped within the files, and store them for searching and analysis.”
Integration and Networking
During operations most of the communication between containers (pods) for our app will happen on the inside of Kubernetes cluster, that’s why we will be able to cross-reference components by Name:Port. A few components will have to be exposed outside of the cluster though. Namely, the client component needs to be exposed outside for end users to be able to download a Single Page Application (SPA) React-based front-end into their browser. By default, the end users can upload their content using a web browser, however, alternatively the content may be delivered directly to the server-side storage for cracking to enable mass ingest. Also, the server component needs to be accessible to the client which runs in a web browser. And finally, the publisher (pub) and subscriber (sub) components should be able to communicate with external components such as Kafka cluster, if it is, for example, necessary to connect the app deployed on Azure Stack Edge to another app deployed on Azure Stack Hub in a Hub-n-Spoke deployment scenario.
While developing the app it may be beneficial to expose the necessary components via NodePort to facilitate debugging, etc. However, for operations it will be suitable to expose the abovementioned components, for example, as LoadBalancers or Ingresses (with Kubernetes external service IPs properly allocated) instead.
Azure Stack Edge can support mixed workloads which include VMs, Kubernetes containers and IoT Edge modules. When you configure Azure Stack Edge appliance, you can set up Network interfaces for different ports to have a Static or Dynamic (DHCP) IP address assignment. To possibly facilitate the future device management and your development efforts it may be beneficial to set up Static IP addresses for ports. Also, while enabling certain port(s) for Compute you can specify Compute IPs for container-based workloads (IoT/Kubernetes). Specifically, Kubernetes node IPs define master node and worker (1) node IP addresses, and Kubernetes external service IPs define a set of IP addresses to be allocated for services exposed outside of Kubernetes cluster. Please make sure to define the sufficient range of IPs for Kubernetes external service IPs which corresponds to the number of services exposed outside of Kubernetes cluster in your app(s), otherwise IP address allocation won’t happen when your service(s) are created. Please note that in case in addition to Kubernetes containers you’ve already deployed, for example, automatically via GitOps and manually via Helm, you also deploy some IoT Edge modules on to Azure Stack Edge via Azure Portal, each of those modules will consume Kubernetes external service IP (corresponding deployment and service objects will be created).
As described here Microsoft Cognitive Services containers submit metering information for billing purposes which currently requires an outbound connectivity.
Performance and Resilience
For the use case we are implementing on the Edge we assume that the volume of incoming data to be ingested in the system per device will be medium or small. It is also fair to assume that we may have multiple Azure Stack Edges with the app installed available to, for example, a disaster response team in the field. The volume per device may still be 100x of MBs to GBs of data (which we may consider a medium-sized volume). However, obviously, running this workload in a larger capacity setup such as on Azure Stack Hub, Azure Modular Datacenter or in the Cloud could enable processing of 100x GBs to many TBs of data.
For this project we focused on a Minimal Viable Product (MVP) architecture to implement the workload without extensive performance optimization such as additional device tuning or using server-side data caching, etc. However, the means for Observability and Monitoring embedded into the app and Azure Stack Edge local Administration Portal may help you identify the performance bottlenecks and possible device operations degradation for these concerns to be addressed intelligently.
Communication and connectivity resilience is often required for field operations, and this is where Azure Orbital capabilities can be leveraged in a broader scenario with Azure Cloud. Azure Modular Data Center (MDC) SATCOM scenario with Network High Availability (HA) module is described here.
High Availability and Disaster Recovery
From the application perspective Content Cracking Pipeline(s) is the most compute-intense component of the architecture. Content Cracking Pipeline(s) orchestrates the ingest workflow and invokes individual functions from the respective containers as appropriate. To ensure the proper availability and adequate performance of critical components (on a critical path) which support the ingest process, multiple pods may be deployed for these components at the same time using Deployments and ReplicaSets exposing their functionalities via LoadBalancers and considering the overall device’s storage and compute capacity. For example, while processing large documents, Linked Entities Extraction and Key Phrase Extraction containers will take advantage of document splitting to be able to process smaller document chucks in parallel. And to extract text from multiple documents at the same time, multiple pods will be available for Text Extraction container.
If you deploy an app on to a single Azure Stack Edge device, from the high availability perspective this device may be considered as a single point of failure (SPOF). In case device in the field loses its power, you may take advantage of an optional Uninterrupted Power Supply (UPS) for Azure Stack Edge to prevent this from happening. In connected scenarios, the storage may be synced with Azure Cloud File Shares as needed.
To implement high availability topologies, you may look at multi-node setups available, for example, with Azure Stack Hub. In case of a disaster situation and you need to stand up a new Azure Stack Edge device with your app(s), the deployment may be automated via GitOps as described here. And if the data needs to be securely preserved or moved to the Cloud or Edge you may leverage Azure Data Box options described here.
Security and Identity
While building architectures for the Hybrid Cloud (Intelligent Cloud, Intelligent Edge, etc.) it is important to follow the Defense in depth principle (DiD) and put the appropriate security controls in different levels of the system.
When it comes to the security on Azure Stack Edge, the device itself can be managed from your computer via a local web UI using a secure Local Administrator account credentials (while your computer is physically connected to the device), the Azure Cloud management can be done using Azure Active Directory (AAD) organization account credentials associated with a valid Azure Cloud Subscription, then for the apps that you build you may have options. We’ll approach those options from the identity perspective. To implement authentication and authorization for your apps you may well be using Azure Active Directory (AAD) claims-based authentication leveraging JWTs as well which should work well if the device is operating in a connected mode. For disconnected mode or occasionally connected mode of operations we would need to produce authentication tokens on the device, thus having, for example, cached AAD tokens available for authentication on the device would be nice.
Because Azure Stack Edge is a managed appliance, logically you won’t be able to install and take advantage of, say, Active Directory Federation Services (ADFS) + Azure Active Directory (AD) Connect locally on the device for on-premises authentication. However, you can implement a custom authentication for your app in a programming language of your choice, for example, leveraging JWTs and bcrypt (or PBKDF2) which perform key stretching of password hashes for security purposes.
When dealing with high security environments, for example, air-gapped environments, security policies and physical security measures become even more important. In such environments we may require secure removable media to get the software and data in/out of the system.
Testability
Writing automated tests and ensuring an adequate test coverage helps to increase the quality of the code and the solution overall. In the micro-services-based architecture you may consider a bottom-up strategy to testing by providing unit tests (individual functionalities), service tests (in/dependent services) and system tests (end-to-end functional flows).
For the front-end in React (JavaScript) you may leverage Jest or React Testing Library as described here. For the backend depending on the language you choose for writing Web APIs, you may leverage xUnit and MSTest (and possibly moq framework) for .NET Core, unittest with Django in Python, testing package or net/http/httptest package in Go, and Mocha & Chai for NodeJS.
Observability and Monitoring
Just like an AI application itself may help to gain meaningful insights about the content it is presented with, gaining insights about how the application is running, its performance, its error states, etc. will also be very important for smooth operations and possible future incremental improvements. Observability helps to obtain these insights by instrumenting a solution to collect and analyze metrics and logs.
In this article we specifically highlight how using ELK stack (Elastic Search, Log Stash and Kibana) allows us to collect exception logs from the application, store them in a dedicated Elastic Search index and query them using Kibana while investigating the causes for common issues. For keeping an eye on time-series-based performance metrics of the app, we can create a dedicated database on Microsoft SQL Server Express and connect Grafana container to it, this way we will know the performance details about user searches, speed of extraction for linked entities and key phrases, speed of extraction for triples, etc., and be able to identify performance bottlenecks. These approaches will work fine in a disconnected mode. Please note that this additional instrumentation will add a certain overhead to the system, however this investment will likely go a long way, for example, if issues need to be troubleshooted or performance of ingest needs to be improved.
For connected mode of operations, you can add the appropriate instrumentation to your client-side and server-side code and by leveraging Microsoft Application Insights container submit the collected telemetry data to Azure Cloud, subsequently you will be able to query and analyze the data on Azure Portal using Application Insights UI.
Scalability and Portability
Azure Stack Edge is currently available in different form factors, for example: Azure Stack Edge Pro, Azure Stack Edge Pro R (this is the exact device we deployed the Enriched Search Experience Project sample Kubernetes app onto) and Azure Stack Edge Mini R, etc. Apart from Azure Stack Edge, Azure Stack family includes Azure Stack Hub, Azure Stack HCI, etc. also including Azure Modular Datacenter (MDC) which is based on Azure Stack Hub. These are just some of the options you may have for implementing you distributed workloads across the hybrid cloud while leveraging containers, VMs and/or IoT Edge modules. For example, you may consider implementing a specialized workload (focused solely on NLP or CV on the Edge) on Azure Stack Edge Mini R, handle a more compute-intense workload on Azure Stack Edge Pro/Pro R (say, NLP + CV at the same time on a single device), and put the most compute-intense workload on Azure Stack Hub (say, aggregation of inputs from multiple Edges and dealing with larger volumes of information). That’s why Hub-n-Spoke use cases and distributed event-driven architectures would make a lot of sense while leveraging, for example, Azure Stack Edge(s) and Azure Stack Hub(s) as a part of a single cohesive solution.
Currently Azure Stack Edge supports single-node Kubernetes cluster and you may take advantage of a multi-node setup, for example, on Azure Stack Hub. From the capacity perspective we may consider the overall capacity of Azure Stack Hub as the aggregated capacity of multiple Azure Stack Edges, and similarly, the overall capacity of Azure Modular Datacenter (MDC) as the aggregated capacity of multiple Azure Stack Hubs.
Because the architecture presented in this article is based on Docker containers orchestrated by Kubernetes, it will be applicable to systems which support Kubernetes. Thus, for example, we could deploy a Kubernetes cluster onto Azure Stack Hub via AKS-Engine or via Azure Stack Hub Marketplace, and then deploy the same app to Azure Stack Hub as well. We could also deploy the same app in Azure Cloud into a dedicated Kubernetes cluster there, however it would be more beneficial to consider a PaaS-based architecture for such deployment instead, because instead of orchestrating containers in the Cloud you might want to leverage the corresponding Azure Cloud PaaS services with respective SLAs.
When building distributed apps across the Cloud and Edge, you may consider combining components running on the Edge in Kubernetes cluster(s) with components running in the Cloud. From this perspective Distributed Application Runtime (Dapr) project may be very interesting because it is well-suited for micro-services, applicable for Kubernetes, leverages a sidecar-based architecture, and suggests an overall programming model for building apps in a Hybrid Cloud and even multi-cloud environments.
Documentation
We believe in both code and application documentation.
Documentation embedded in the application itself which intuitively describes the main proposed functional flows may significantly increase the adoption of your app by the end users. In case you are building a web app which is accessed in the web browser you could embed your application documentation in the User Interface (UI) of you app. Last but not the least in this list.
Documenting your code responsibly is very important for sharing the knowledge across your team(s), troubleshooting and supportability of the code, etc. Modern Web APIs are typically described based on Open API specification with the help of Swagger and most of the modern programming languages have means to help your autogenerate Web API documentation based on your code. Specifically, you might consider using Swashbuckle.AspNetCore NuGet package if you are building .NET Core Web APIs, PyYAML and uritemplate PyPl package for Web API built using Python and Django, swagger-jsdoc and swagger-ui-express npm packages for NodeJS-based Web APIs (Express), and swag library for Web APIs written in Go (golang).
OSS and Licensing
Nowadays modern micro-services-based architectures may include many components from different vendors and/or Open Source Software (OSS) components. Many GitHub projects have already become ubiquitous, for example, Docker containers, Kubernetes container orchestrator, Istio service mesh, Kafka event streaming, MongoDB NoSQL database, ElasticSearch full text search, Redis in-memory database, Kubeflow for MLOps, etc. GitHub provides a guidance for choosing the right license which can be found here. It refers to the https://choosealicense.com/ web site for more details. OSS Licensing strategy is often times a joint initiative with multiple groups involved in your organization including legal, software development, product development, finance, etc.
For example, the architecture above includes ELK stack from Elastic. In the past ElasticSearch and Kibana were both licensed with Apache 2.0 license, but starting from January 14 2021 Elastic changed the licensing for ElasticSearch and Kibana to be dual licensed under Server Side Public License (SSPL) and the Elastic License as described here. These changes would have to be properly evaluated and impacts assessed for existing or brand-new projects.
The same licensing considerations would apply to, for example, using Stanford Core NLP (which is currently licensed with GNU General Public License) or ClausIE (which is currently licensed with Creative Commons Attribution-ShareAlike 3.0 Unported License).
Deployment Automation and DevOps
In another article here we shared a point of view on deploying Kubernetes applications on Azure Stack Edge by Azure Arc for Kubernetes through GitOps with GitHub or GitLab.
When configuring Azure Stack Edge and creating a dedicated username, you will be able to retrieve kubectl configuration for connecting to the Kubernetes cluster on Azure Stack Edge from your local computer. This may come handy when you are still developing your app and need a controlled granular re-deployment of its components. Then with kubectl (and Helm) installed locally on your computer you will be able to conveniently re-deploy your app’s components, for example, via Helm from CLI.
Showcase
If you would like to see an example of a sophisticated Artificial Intelligence (AI) app deployed on Azure Stack Edge using GitOps, you are welcome to watch a Channel 9 video here. Enriched Search Experience Project sample Kubernetes app on Azure Stack Edge is a proof-of-concept project and leverages circa 30 different container images to implement a knowledge mining workload on the edge. Please note that the application showcased in the video may have similar but not exactly the same architecture to the one described in this article.
Disclaimer
Opinions expressed are solely of the author and do not express the views and opinions of author’s current employer, Microsoft.
Books you might enjoy reading
You might enjoy reading the following books you have probably noticed on the front cover of this article:
- “Design Patterns: Elements of reusable object-oriented software” by Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides (1994) (link)
- “Designing Distributed Systems: Patterns and paradigms for scalable, reliable services” by Brendan Burns (2018) (link)
- “Building Microservices: Designing fine-grained systems” by Sam Newman (2015) (link)
- “Kubernetes Up & Running: Dive into the future of infrastructure” by Brendan Burns, Joe Beda & Kelsey Hightower (2017, 2019) (link)
- “Kubernetes Patterns: Reusable elements for designing cloud-native applications” by Bilgin Ibryam & Roland Huß (2019) (link)
- “Managing Kubernetes: Operating Kubernetes clusters in the real world” by Brendan Burns & Craig Tracey (2018) (link)
- “Kubernetes Operators: Automating the container orchestration platform” by Jason Dobies & Joshua Wood (2020) (link)
