
Deploying AI Models in Azure Cloud
Based on the project experiences working on AI (Artificial Intelligence) & ML (Machine Learning) projects with AML (Azure Machine Learning) platform since 2018 in this article we will share a point of view (the good parts) on bringing your AI models to production in Azure Cloud via MLOps. It is a typical situation when the initial experimentation (a trial and error approach) and the associated feasibility study to produce a certain model takes place in AML/Jupyter Notebook(s) first. Once some promising results have been obtained, analyzed and validated via the feasibility study by the Machine Learning Engineering team “locally”, the Application Engineering and DevOps Engineering teams can collaborate to “productionalize” the workload at scale in the Cloud (and/or at the Edge as needed). While automating CI/CD for a specific AI/ML workload there is a number of common challenges (as also partially highlighted here) to be solved as following:
- CI (Continuous Integration)/CD (Continuous Delivery) automation itself
- Environments strategy/process (Models development and promotion, etc.) and Infrastructure automation
- Data Integration (Switching from files to databases/data warehouses, etc.)
- Security (Authentication, Authorization, etc.)
- Performance (Models distributed training, Real-time or batch inferencing, etc.)
- Continuous Improvement (Models retraining, data (re)labelling, feedback loop, etc.)
- Testability
- Observability and Monitoring
- and more …
Platform
AML (Azure Machine Learning) is an MLOps-enabled Azure’s end-to-end Machine Learning platform for building and deploying models in Azure Cloud. Please find more information about Azure Machine Learning (ML as a Service) here, and more holistically on Microsoft’s AI/ML reference architectures and best practices here. The taxonomy of Azure Machine Learning platform is shown on the following diagram as described here:

In the center of the universe is Azure Machine Learning workspace which from the infrastructural perspective is dependent on the following Azure resources as described here:
- Azure Storage account
- Azure Container Registry
- Azure Application Insights
- Azure Key Vault
There are multiple ways of interacting with Azure Machine Learning workspace which include the following as described here in the Reference section:
- AML Python SDK (described here)
- AML CLI (described here) which is an extension of Azure CLI
- AML REST API (described here)
AML Python SDK is great for development and automation, AML CLI is more convenient for Dev(Sec)Ops/MLOps automation, and AML REST API is a lower level interface which is typically not used on projects in favor of the former 2 approaches. More context about CLI-focused and Python-focused approaches can be found here.
Noteworthy: From the security perspective the 4 abovementioned Azure resources will be associated with Azure Machine Learning workspace and have separate security keys. Associated Azure Key Vault is a central place where security keys are maintained for Azure Machine Learning workspace, and in case you need to rotate (change) security keys for Azure Storage account, Azure Container Registry and Azure Application Insights, there’s a procedure for that using AML CLI az ml workspace sync-keys command as described here.
Process
To automate CI/CD for a specific AI/ML workload (based on a single or multiple models, or ensemble(s) of models) different Dev(Sec)Ops/MLOps pipelines can be leveraged as described here:

Azure DevOps provides a central point for organizing the entire MLOps process based on multiple pipelines. This is how different MLOps pipelines might look like for a project in Azure DevOps:

Architecture
The following diagram illustrates the entire SDLC (Software Development LifeCycle) and a sample solution architecture:

In the diagram above different Azure DevOps pipelines interact with different elements of Azure Machine Learning platform:
- Data-Pipeline <-> Datastores, Datasets
- Environment-Pipeline <-> Environments
- Code-Pipeline (CI) <-> AML Python SDK (code)
- Training-Pipeline <-> Experiments, Pipelines, Models
- Deployment-Pipeline (ACI) <-> Endpoints
- Deployment-Pipeline (AKS), Canary-Deployment-Pipeline (AKS) <-> Endpoints
Noteworthy: Different technologies used on the diagram include but not limited to Azure Storage & Compute services, and more specifically, Azure Machine Learning (AML), Azure DevOps, Azure Blob Storage, Azure Data Factory, Azure Container Registry, Azure Container Instances (ACI), Azure Kubernetes Service (AKS), etc.
This architecture is based on the canonical MLOps (MLOps on Azure) architecture described here and its offspring, MLOpsPython (MLOps with Azure ML) architecture, described here.
A simple starter boiler-plate CI/CD YAML pipeline for MLOps can be found inside of Azure DevOps itself as shown below:

The YAML for this basic all-in-one CI/CD template pipeline looks like the following:
Noteworthy: AML CLI az ml folder attach command provides a contextual awareness for the subsequent AML CLI commands in Azure DevOps pipeline. Thus, if AML CLI az ml folder attach is not involved, then you will be expected to explicitly provide --workspace-nameand --resource-group parameters into the respective AML CLI command such as az ml model deploy as necessary.
Inferencing
Considering inferencing, we’ll review an example of a simple Scikit-Learn model (for unsupervised learning, clustering using kmeans algorithm) and its deployment into Azure Container Instances (ACI) and Azure Kubernetes Services (AKS) facilitated by Azure Machine Learning platform.
Azure Machine Learning facilitates the deployment to Azure Container Instances (ACI) as well as to Azure Kubernetes Services (AKS). Below we illustrate how a model gets packages and deployed into Azure Container Instance (ACI) and how this deployment looks like under the hood.

Similarly, the next illustration depicts the deployment to Azure Kubernetes Service (AKS) and how the resulting deployment looks like in Azure portal.

Noteworthy: Azure Machine Learning platform builds container images for deployment of the inference code based on a standard image template (or a custom image you may choose to specify as necessary).
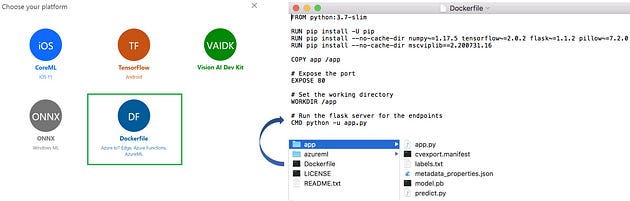
Interestingly enough, when we review an exported model built using Azure Custom Vision portal (here), we can also see how the same packaging and deployment mechanism based on Azure Machine Learning platform is being used there too. We’ve already highlighted this fact in our previous article here (on the image here).

TensorFlow model file model.pb, labels file labels.txt, scoring Python script score.py, Python API app app.py, and Docker Dockerfileleveraging Python flask server
Speaking about security of real-time endpoint(s), when deploying a model to a Web Service in a traditional way the authentication options will depend on the deployment target. Namely, key-based authentication can be enabled when deploying into ACI, this way your deployed endpoint from the authentication perspective will resemble Azure Cognitive Services which can be accessed with apiKeys. For AKS route you can leverage a token-based authentication or key-based authentication. Please also note that the new way of handling Real-time endpoints deployments via AML Endpoints will be becoming the mainstream once AML Endpoints and Deployments functionality graduates from the Public Preview. Please find more information about AML Endpoints and Deployments here.
Training
Considering training, we’ll review an example of a supervised learning HuggingFace NLP transformer model (BERT or DistilBERT) and its training on CPU-based and GPU-based Compute provided by Azure Machine Learning platform. Please find more information about HuggingFace transformer models here and here.
Noteworthy: Before continuing on with training considerations we’ll take a slight detour to highlight the way HuggingFace transformer models are packaged and how this can be leveraged during deployment(s). Specifically, as shown below trainer.save_model() produces config.json, pytorch_model.bin and training_args.bin files; and tokenizer.save_pretrained() produces the other 3 json config files and vocab.txt file. More information about the purpose of these files can be found here. Also for the convenience of future scoring you may choose to include label2id and id2label conversions right into the config.json as a part of your training code.

By the contrast with Real-time Endpoint for inference which is supposed to be exposed for external consumption by design, the AML Training Pipeline Endpoint is considered to be more like an “internal” resource, that defines the options you have for authentication for AML Training Pipeline Endpoint as described here and here.
Continuous Improvement of a model is a common expectation in a project, this means that when the model code changes we are going to need to repackage pipeline steps and retrain the model appropriately. From the automation perspective this means that if AML Training Pipeline is published and accessible on AML Training Pipeline Endpoint via URL, this allows to retrain the model on demand when data changes (for example, a new labelled or unlabeled data arrives) and/or code changes. From the maintenance perspective it would be convenient to maintain versions of the pipeline while keeping the endpoint URL fixed instead of re-publishing numerous pipelines/endpoints on different URLs. Azure Machine Learning supports versioned AML Training Pipeline Endpoints as described here and here. Below we provide an illustration of how to turn a published pipeline into a versioned pipeline endpoint using AML Python SDK in Azure Machine Learning (please note how subordination happens between steps 2 and 3 and how the icons change):

According to its Swagger definition (for example, for EastUS region here) AML Training Pipeline Endpoint may be invoked via ID (dynamic value which is generated after AML Training Pipeline Endpoint gets deployed) or Name (static value which is typically known upfront). For repeatability in DevOps it may be convenient to call AML Training Pipeline Endpoint by Name instead of ID, this may make is easier for any upstream applications or services which will need to invoke AML Training Pipeline Endpoint on-demand:

Noteworthy: When invoking AML Training Pipeline Endpoint by Name, the name is a query parameter to be supplied in the URL. Also pipelineVersion may be supplied as a query parameter, in case no pipelineVersion is supplied explicitly, the default pipelineVersion deployed will be assumed. Other static parts of the URL will be provided as path parameters such as subscriptionId, resourceGroupName and workspaceName.
For complex Deep Neural Network (DNN)-based models it is common to have a requirement for GPU-based distributed training on compute cluster(s). The reference architecture for distributed training of Deep Neural Networks on Azure using Azure Machine Learning is described here. More information about distributed GPU training can be found here, here and here. This guidance also highlights some framework (for example, Tensorflow or PyTorch) and model (for example, HuggingFace) specific aspects of distributed training. For example, there is a more generic guidance on Open Message Passing Interface (MPI) as well as a more specific guidance on HuggingFace transformer models PyTorch distributed training options, also highlighting how Azure Machine Learning platform supports these options and what environmental variables the platform provides. Specifically, for HuggingFace transformer models there are 2 main options available for distributed training:
- Per Node (per-node-launcher using PyTorch
torch.distributed.launchlibrary) - Per Process (per-process-launcher)
Azure Machine Learning platform facilitates the setup by providing a number of environmental variables such as MASTER_ADDR, MASTER_PORT, WORLD_SIZE, NODE_RANK, RANK, LOCAL_RANKin the context of container image(s) running the distributed training code. As described here and here, when using Per Process option for distributed training of HuggingFace transformer models, you have to explicitly provide local_rank parameter (which defined the rank of the process during distributed training) in transformers.TrainingArguments class object based on RANKenvironmental variable. Below we illustrate how to enable distributed training for a HuggingFace transformer model Per Node or Per Process using AML Python SDK:

We already mentioned earlier that for repeatability and reproducibility of models in case of model code changes or data changes AML Training Pipelines are set up and published. Azure Machine Learning provides 2 main ways to define training pipelines and package your training code for re-execution:
- AML Training Pipelines in AML Python SDK
- AML Training Pipelines in YAML as described here
Essentially, when we use AML Python SDK to define AML Training Pipeline code, we are going to have a Python file (for example, pipeline.py) which describes pipeline’s steps, and each step may be implemented as a separate Python file (for example, train.py) and plugged in into the pipeline as a PythonScriptStep. When we use YAML to define AML Training Pipeline configuration, we are going to have a YAML file (for example, pipeline.yaml) which describes pipeline’s steps, and each step may still be implemented as a separate Python file and still referenced to as PythonScriptStep.
Noteworthy: When switching from the notebook into a scripted training pipeline the authentication may be taken care of with the help of AzureCliAuthentication class as illustrated below.

Below we briefly illustrate how to package your training code into AML Training Pipeline using Python SDK route and YAML route:

Noteworthy: When the pipeline runs each pipeline step (and its associated Python code for PythonScriptStep’s) will be packaged and executed in a separate container. This allows different steps to be executed on different compute targets which comes handy when, for example, more resource greedy training code takes advantage of GPU-based compute while less resource greedy code is executed on CPU-based compute.
One caveat related to AML Training Pipelines in YAML is that there is only certain types of steps which are currently supported in YAML as described here. For example, for distributed training of HuggingFace transformer models Per Node using AML Python SDK to invoke PyTorch torch.distributed.launch library a CommandStep(here) can be used, however for AML Training Pipelines in YAML the CommandStepis not currently supported. That’s why for distributed training of HuggingFace transformer models in YAML we can leverage Per Process option and a supported PythonScriptStep. Below we briefly illustrate how distributed training Per Node and Per Process looks like under the hood:

Another nuance is related to the fact that when providing nodeCountand processCount in the distributed config (YAML) into the YAML definition of AML Training Pipeline it looks like the processCount setting is not taken into consideration. More details about how pipeline steps are packaged and submitted for execution can be found in Azure Machine Learning studio by navigating to the associated Experiment page > Details tab > See all properties section > Raw JSON button. This JSON contains a runDefinition section which submitted config settings. One way to overcome this challenge is to use a multi-node compute with a single GPU per node, this way you can establish a PythonScriptStep for a distributed training of HuggingFace transformer model Per Process identical to Per Node setup. One of the downsides there would be that Per Process (~Per Node) setup with, say, 8 nodes with a single GPU on each node will take longer to warm up comparing to, say, 2 nodes with 4 GPUs on each node (the total GPUs would be the same in both cases), while from the cost perspective these 2 setups might be the same.
Noteworthy: While setting up a distributed training for HuggingFace transformer model using Open MPI (here) approach ("framework": "Python", "communicator": "Mpi") we received the following error: Error initializing torch.distributed using env:// rendezvous: environment variable RANK expected, but not set even after providing the local_rankargument in ftransformers.TrainingArguments class object.
To conclude with considerations about distributed training and AML Training Pipelines in YAML, there are some exciting new improvements coming up with AML CLI (v2) related to AML Jobs in YAML format as described here and here.
Depending on project requirements it may be convenient to initiate model(s) retraining process from the “inside” of AML (say, from AML itself or via DevOps on behalf of an identity which has access to AML, for example, with assigned Contributor or Owner roles) or from the “outside” of AML (say, from Azure Function or other Azure hosted app or service).
Speaking about invocation from “inside”, the following code snippet illustrates how to execute AML Training Pipeline from Azure DevOps pipeline (which may run periodically on schedule):
In this code by using AML CLI (v1) approach we first retrieve a list of published pipelines by Name and assume that on the top of that filtered list is the latest (default) published endpoint which we want to invoke.
Speaking about invocation from “outside”, the official documentation for Azure Machine Learning provides examples of how to invoke AML Training Pipeline Endpoint from outside by leveraging a token-based authentication with SPN (Service Principal) for different languages: NodeJS, Python, Java. We’ve adopted the Java code snippet to arrive at the following code snippet for C# .NET Core Console App (using a minimalistic REST approach with just HttpClient) calling AML Training Pipeline from outside on behalf of an SPN:
This SPN needs to have at least 2 permissions granted to AML according to the principle of the least privilege:
- Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action
- Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read

You can find more information about common scenarios around securing access to AML here.
The official documentation also provides an example of how to use a managed identity to obtain an access token for Azure resource(s) here. We’ve adopted this code in the context of Azure Function(s) to arrive at the following code snippet which can be used for Azure Function Managed Identity or User Assigned Managed Identities calling AML Training Pipeline Endpoint from outside:
The difference between using a User Assigned Managed Identity versus using a Managed Identity will be in supplying or not supplying client_id in GetAmlAccessToken function. Also IDENTITY_ENDPOINT and IDENTITY_HEADER environmental variables are provided by the platform inside of Azure Function runtime as described here. Thus practically we can also see the difference between access tokens issued with SPN versus with MSI as shown below:

The appidacrclaim indicates the type of client authentication performed. For a confidential client, the value is 1 when a shared secret (a password) is used as a client secret and 2 when a certificate is used as a client secret. The value 0 indicates a public client, which does not provide a client secret and therefore does not authenticate to the STS.
Noteworthy: In the code snippets above you might have noticed that an empty payload is sent along with the POST request while invoking AML Training Pipeline Endpoint. This is because otherwise you may receive an error “Object reference not set to an instance of an object” as shown below:

By its nature training of complex models is a lengthy task which can practically take hours or days. When the training process is kicked off in Azure DevOps pipeline via AML CLI (for example, by using az ml run submit-pipeline command), the pipeline itself will be successfully completed once the command is executed, in fact, the actual training process may then be monitored in Azure Machine Learning in the associated Experiment Run. On practice, when the model training code changes and a new PR (pull request) is submitted it is important to make sure that the training process completes successfully. Thus for the Eventual Consistency between Azure DevOps and Azure Machine Learning it may be beneficial to update Azure DevOps pull request status based on the result of Azure Machine Learning Experiment Run execution of model training (Succeeded or Failed). This can be achieved by implementing a Callback mechanism from Azure Machine Learning training pipeline back to Azure DevOps via Azure DevOps REST API. Practically, a new PythonScriptStep may be added to the very end of Azure Machine Learning training pipeline (after model training and evaluation steps) which will update the status of Azure DevOps pull request upon completion of the training process in Azure Machine Learning. Azure DevOps authentication options are described here. For the purposes of non-interactive authentication in Azure DevOps, for example, you may want to choose a PAT (Personal access token)-based authentication as described here. Then by following this guidance and the following common pattern VERB https://{instance}[/{collection}][/{team-project}]/_apis[/{area}]/{resource}?api-version={version} we may implement the actual HTTP callback to update Azure DevOps pull request status according to this spec, also supplying the personal access token for Azure DevOps (its Base64 string representation to be precise) through an HTTP header. In Python you may take advantage of your favorite HTTP requests library such as, for example, requests or http.client.
Training pipeline structure
Practically, most of the real-world training pipelines are Data-Driven and there’s a need to move data in/out of the pipeline and/or between its steps as described here. In this section we highlight how to get started on a project with a simple project template and how to set up a Data-Driven AML Training pipeline where arguments (parameters) are passed between the steps.
MLOpsPython template available here with its bootstrap procedure (here) may give you a jump start on your project. You can find its code description here and it is also presented below for your convenience.

Apart from the MLOpsPython template, you can also find a lot of code and examples of GitHub for building AML Training pipelines, for example, a comprehensive guidance here or a simple demo here, etc. However we stick with the MLOpsPython template/sample from here to illustrate how a typical multi-step AML Training pipeline is built using AML Python SDK. Specifically, the following illustration explains how parameters are passed from Azure DevOps into AML Training pipeline, and furthermore how parameters are then passed between steps inside of AML Training pipeline, all with the help of Python standard argparselibrary.

Then when you run the pipeline you may examine the graphical representation of the pipeline under the associated experiment and verify that the steps are connected in the anticipated way and the parameters have been passed appropriately.

When the pipeline executes you may also examine the execution logs for the steps. Below illustration shows how PipelineDataobject has been used to pass the data between AML Training Pipeline steps (Train step and Register step).

Also the same pipeline (pipeline.py) may be represented in a form of YAML (pipeline.yaml) as illustrated below:
When using YAML representation of AML Training Pipeline we still need means to specify the order of steps execution (unlike using run_aftercall to force the order for pipelines defined via AML Python SDK). The order will be implied because of dependencies between inputs and outputs between steps, and this is exactly the modification we made to properly connect the steps by using 3 PipelineDataobjects (A, B and C) as shown below:

Noteworthy: When AML Training Pipeline runs, this is done in the context of an experiment run (you may find a descriptive diagram of this process here). Azure Machine Learning provides a Run object (as described here) accessible within your AML Training Pipeline code. As a typical AML Training Pipeline consists of multiple steps with each step running in its own Docker container (possibly even on different compute clusters), step’s run context is available via runobject, and the parent pipeline run overall context is accessible viarun.parentobject. This may come handy in case we need to communicate some information between steps of the pipeline, for example, by tagging the overall pipeline run with tags from certain step(s) and then reading those tags on subsequent step(s) instead of formally passing parameters between steps via code.
Training data
Azure Machine Learning provides a Datastore concept which allows to connect to different types of storage services in Azure as described here. Some of these datastore types (for example, Azure Blob Storage, Azure File Shares) provide a static data while others (for example, Azure SQL Database) provide a dynamic data (say, based on a query). This practically means that if you have a Data Preparation step in your training pipeline which is dependent on a set of files in Azure Blob Storage (in the associated Dataset) you would need to make sure to update (re-upload) those files in case the data changed. On the other hand, if your Data Preparation step is leveraging a “live” connection to a database, the data will be current in accordance with a query for the associated Dataset. In some cases it makes sense to move the data from one type of storage into another (for example, from a database into a blob storage), and for these purposes aDataTransferStepmay be used as a part of your training pipeline.
Environments and Deployment strategy
The process of building AI/ML models and bringing them to production includes a lot of checks & balances with multiple stakeholders involved and multiple environments established to support the necessary procedures. The process reference and the environments guidance can be found here in the MLOps Python reference architecture as illustrated below.

On this diagram a number of environments are highlighted such as Dev/Test, Staging/QA and Production. Azure Machine Learning platform provides an integrated Deployment automation (AML Deployment Strategy) which allows to deploy your models into Azure Container Instances (ACI) and Azure Kubernetes Services (AKS) with a help of convenient AML Python SDK and/or AML CLI. However you may choose to leverage Your Own Deployment Strategy outside of AML, in this case, you may package your models out into Docker container images, put them into a dedicated Azure Container Registry (ACR) and then deploy them into a dedicated Azure Kubernetes Service (AKS) or possibly as Azure Function App or Azure Web App depending on the requirements. This Hybrid Deployment Strategy (AML Deployment Strategy + Your Own Deployment Strategy) is illustrated below.

More guidance on this topic can be found here, here and here. And in this section we will provide an additional illustration of how you may package your model out of AML into a Docker container image using az ml model packageAML CLI command and how the result looks like.

As described here the package template is presented below for the reference.
Now if you need to move container images between ACRs (for example, Non-production and Production) this may be done with the help of az acr import CLI command as described here.
Typically, models get deployed into Azure Container Instances (ACI) in Dev/Test environment and/or Staging/QA environment with a smaller infrastructural footprint, and then Azure Kubernetes Services (AKS) are leveraged for Production deployments at scale. The overall model promotion lifecycle typically involves tagging models with appropriate tags (to distinguish between work-in-progress models and models which are candidates for production) as well as manual release gates to ensure the necessary rigor before a model makes its way to production. Practically, handling production model metadata and versioning as a declarative configuration checked-in into the repo (in a dedicated branch based on a pull request) helps to ensure the accountability and aids in the case you need to reverse an erroneous deployment to the latest stable state.
Infrastructure and MLOps
From the pure infrastructure perspective there are multiple options which may be used to deploy the necessary infrastructure for AML and AML resource itself. For example, ARM templates or Bicep, or Terraform. More information about what AML objects may be deployed via Terraform (in addition to the usual Azure resources such as Azure Storage, etc.) can be found here:
- Azure Machine Learning workspace (azurerm_machine_learning_workspace)
- Azure Machine Learning compute cluster (azurerm_machine_learning_compute_cluster)
- Azure Machine Learning computer instance (azurerm_machine_learning_compute_instance)
- Azure Machine Learning inference cluster (azurerm_machine_learning_inference_cluster)
DevOps and MLOps
As described in this article Azure DevOps is very well equipped to orchestrate all necessary MLOps processes in concert with Azure Machine Learning platform. In fact, there are other options available for such orchestration, for example, GitHub Actions. As described here GitHub Actions provide a set of actions integrated with Azure Machine Learning for deploying Machine Learning models into Azure. The list of relevant Azure Machine Learning Actions is provided below:
- aml-workspace - Connects to or creates a new workspace
- aml-compute - Connects to or creates a new compute target in Azure Machine Learning
- aml-run - Submits a ScriptRun, an Estimator or a Pipeline to Azure Machine Learning
- aml-registermodel - Registers a model to Azure Machine Learning
- aml-deploy - Deploys a model and creates an endpoint for the model
Tooling and Developer Productivity
In our experience using Visual Studio Code for Python development and testing increases your developer productivity. Visual Studio Code comes with a lot of useful features and plugins. Just to mention the only one here, we highlight how Python code formatters and linters allow you to write your code cleaner in the first place (the first time), so you don’t need to address these concerns separately and spend additional time on code cleanup when you are about to submit a pull request into the main branch. Visual Studio Code conveniently suggests you options for Python formatters such as black, autopep8 or yapf, and Python linters such as flake8.

Disclaimer
Opinions expressed are solely of the author and do not express the views and opinions of author’s current employer, Microsoft.

{kind=link}